python之urllib.request向今日头条请求数据 作者:马育民 • 2019-01-15 11:15 • 阅读:10167 # 概述 今日头条与搜狐等网站不同,是通过 [AJAX](http://www.malaoshi.top/show_1EF2cBLj7q5t.html "AJAX") 向web服务器发请求,服务器返回 [JSON](http://www.malaoshi.top/show_1EF2cBZyuggx.html "JSON") 数据 # 通过谷歌浏览器查看 [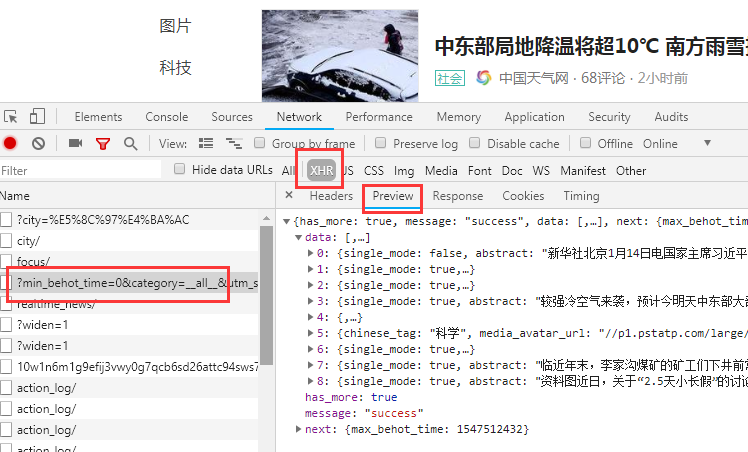](http://www.malaoshi.top/upload/0/0/1EF2cBok8ihD.png) 如上图: 1. 通过谷歌浏览器访问今日头条 2. 点```F12```,点击“XHR”(XML Http Request,是ajax的核心)进行过滤,左侧的都是ajax的请求 3. 点击左侧红框处的类似连接 4. 在右侧是该请求的详细信息,点击“Preview”可以预览响应数据 # 代码 ```python # coding=utf-8 from urllib import request url = r'https://www.toutiao.com/api/pc/feed/?max_behot_time=1547512432&category=__all__&utm_source=toutiao&widen=1&tadrequire=false&as=A1357CA3BD43CFB&cp=5C3DC39CAFDB6E1&_signature=acfuYRAbNf7D6K7h5kTiKGnH7n' #必须发送user-agent请求头,否则不返回数据 headers={ 'user-agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36' } req=request.Request(url, headers=headers) with request.urlopen(req) as resp: print(resp.status, resp.reason,resp.version) print(resp.headers) if resp.status==200: data = resp.read() contenttype=resp.getheader('Content-Type') print( data.decode('utf-8')) ``` 返回的数据是json格式数据,是字符串类型 原文出处:http://www.malaoshi.top/show_1EF2cBxMheSI.html