python之BeautifulSoup4解析html 作者:马育民 • 2019-01-15 17:07 • 阅读:10454 # 概述 Beautiful Soup是python模块,用于解析html、xml文件,提取想要的数据 python解析html的模块有很多,经过大量查看比对,目前该模块优点较多,目前也最火 Beautiful Soup 并没有解析html的功能,也就是说还需要安装解析html的解析器,然后调用解析器处理html,提取数据,过程如下图: [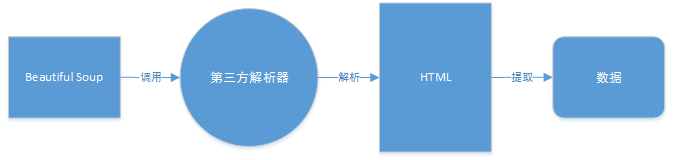](http://www.malaoshi.top/upload/0/0/1EF2denNIAVg.png) 当前最新版本是4,所以一般称之为 **BeautifulSoup4** 或者 **bs4** 官方网址 https://www.crummy.com/software/BeautifulSoup/ 中文api文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html 本课程是依据官方api文档讲解 # 安装 ``` pip install beautifulsoup4 -i https://pypi.douban.com/simple ``` # 解析器的比较 [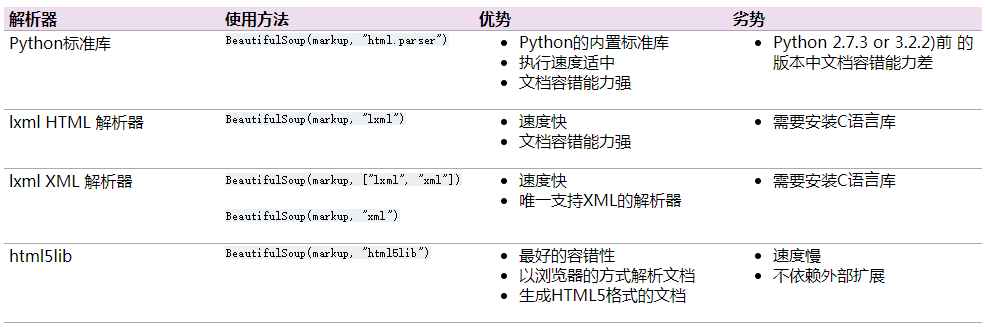](http://www.malaoshi.top/upload/0/0/1EF2d1RaH14S.png) 当前推荐使用内置解析器 **html.parser** # 常用方法 官方文档写的很详细,这里只介绍常用的功能,以及官方文档 **没有写的方法** ### 创建BeautifulSoup对象 读取html文件: ``` from bs4 import BeautifulSoup soup=BeautifulSoup(open('index.html',encoding='utf-8'),'html.parser') ``` 读取html字符串: ``` from bs4 import BeautifulSoup html=''' <html><head><title>html标题</title></head> <body> <p class="title"><b>文章标题</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> ''' soup=BeautifulSoup(html,'html.parser') ``` # 搜索文档树 使用bs4,可以很方便的找到某个标签 主要有3种查找方式: 3. **css选择器** 1. find_all() 2. find() 由于css选择器使用简单(与css选择器相同),功能十分强大,代码量少,推荐使用css选择器, 官方链接:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id37 ### 语法 ``` Tag.select('') ``` **返回** list类型,其元素是Tag ### 按照标签名搜索 ``` l=soup.select('p') print(type(l)) print(l) ``` 结果 ``` <class 'list'> [<p class="title"><b>文章标题</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p>, <p class="story">...</p>] ``` ### 通过属性值查找 ``` l=soup.select('p[class="title"]') print(l) ``` 更多搜索方式参见链接: https://blog.csdn.net/amao1998/article/details/82663978 ## 获取html源代码 ### 语法 ``` Tag.prettify() ``` **返回** 字符串类型,美化的html源代码 ### 例子 ``` l=soup.select('p[class="title"]') print(l[0].prettify()) ``` ## 获取标签中的文本 ### 语法 ``` Tag.text ``` 标签内的文本 ### 例子 ``` l=soup.select('p[class="title"]') print(l[0].text) ``` ## 获取标签中的属性值 ### 语法 ``` Tag['属性名'] 或者 Tag.get('属性名') ``` **注意:** - class属性,返回的是list - 其他属性,返回的是字符串 ### 例子 ``` l=soup.select('a') for item in l: print(item['href'],item.get('id'),item.get('class'),sep=' , ') ``` 结果: ``` http://example.com/elsie , link1 , ['sister'] http://example.com/lacie , link2 , ['sister'] http://example.com/tillie , link3 , ['sister'] ``` ## 修改标签属性 ### 语法 ``` Tag['属性名']=值 ``` 官方链接:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id41 ### 例子 给标签增加id属性,值为t ``` title['id']='t' print(soup) ``` ## 删除标签 将当前节点移除文档树并完全销毁 ### 语法 ``` Tag.decompose() ``` 官方链接:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#decompose ### 例子 ``` a=soup.select('#link1')[0] a.decompose() print(soup) ``` 感谢: https://blog.csdn.net/amao1998/article/details/82663978 https://blog.csdn.net/qq_41654985/article/details/81017569 原文出处:http://www.malaoshi.top/show_1EF2cHTaZSZF.html